
本日のメニュー:Rを使ってエクセルを加工し、Pythonに渡す
前回、Google Colaboratoryを使って、PythonとRを両方とも実行できるようにしました。

今回は、Rを使って中身が直接データとして読み込みにくい(ぐちゃぐちゃな)エクセルデータから、エクセルを使わずにデータを取り込んで整形し、RからPython、PythonからRにデータを受け渡す方法を解説します。
なぜエクセルを使わずにエクセルの中身を加工するのか?
エクセルやCSVのデータを加工するなら、直接エクセルで編集すればいいじゃないか、と突っ込まれそうなので、エクセルを使わないメリットをいくつかあげます。
- 元データを加工しなくていい(新たなデータを管理する必要性がない)
- ファイル数が増えると都度エクセルで加工するのは大変(マクロ作成も大変)
- 大きなデータをエクセルやマクロで処理するのは時間がかかり過ぎる
- そもそもバカでかいデータはメモリを使い過ぎて、エクセルで読み込めない
- 複数のファイルを一気に取り込める
手順
- Google Colaboratoryの準備(ドライブのマウント)
- オープンデータのダウンロード(eStat 政府統計データ)
- Googleドライブのフォルダにデータを入れる
- Rの必要なパッケージのインストールとパッケージの保存方法
- Rを使ってデータを閲覧(head, datatable)
- Rを使ってデータを加工
- 加工したデータをRからPythonへ、PythonからRへ受け渡す方法
データを読み込んで加工してみよう
データを読み込む前に、保管場所を確保します。
Google Colaboratoryの準備(ドライブのマウント)
最初にGoogleドライブと連携できるようにします。Google Colaboratoryで作業するフォルダは作業が終わるとコード以外は消えてしまうので、データは消されない場所に入れます。
まずはGoogle Colaboratoryにログインしましょう。
ファイルから「ノートブックの新規作成」をクリック。
ファイル名は適当につけます。(ここでは「R_Python_linkage.ipynb」とします)
以下のフォルダのアイコンをクリックします。
以下をクリックします。
「Googleドライブのファイルへのアクセスを許可しますか?」と表示されたら、「Googleドライブに接続」をクリックします。

はじめての場合は、以下のようなコードが出現するので、▶をクリックして実行します。
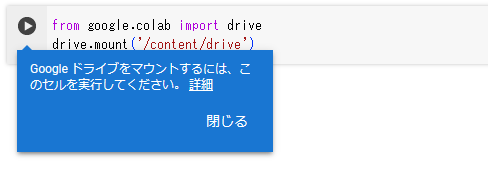
アクセスできる情報は「すべて選択」を選択して、「続行」をクリックします。
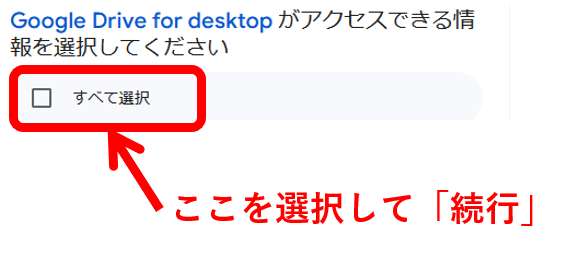
以下のように「drive」が出てきたら、Googleドライブのマウントができています。
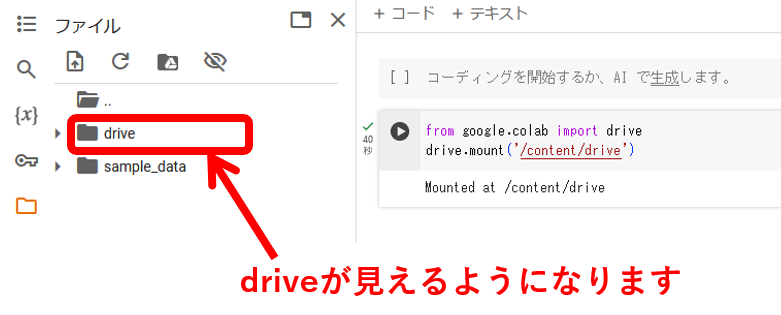
drive以下をクリックしていくと、フォルダの中が確認できます。
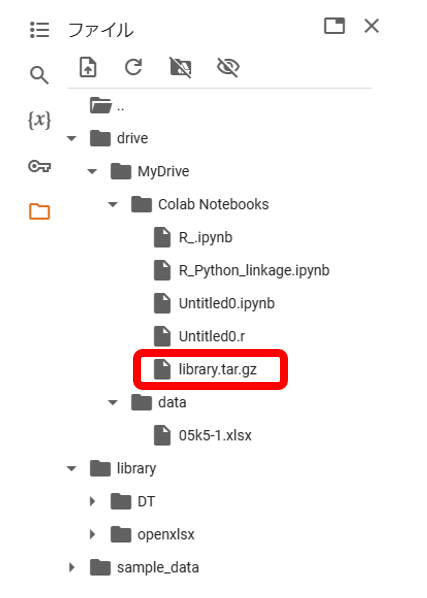
作成している「R_Python_linkage.ipynb」は「Colab Notebooks」にあります。
消されたくないデータはdriveに入れるか、別途管理しましょう。
オープンデータのダウンロード(eStat 政府統計データ)
今回は、eStatの政府統計データを使って、データ加工を実践してみます。
まず、以下のURLにある、「男女別人口(各年10月1日現在)- 総人口、日本人人口(2000年~2020年)」をダウンロードします。
人口推計 長期時系列データ 長期時系列データ(平成12年~令和2年) | ファイル | 統計データを探す | 政府統計の総合窓口 (e-stat.go.jp)
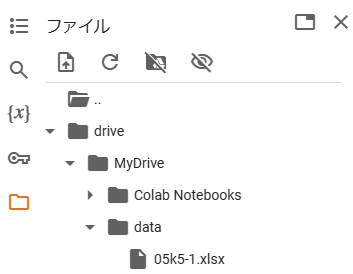
「05k5-1.xlsx」というファイルがダウンロードされます。今回は、このデータをdriveに入れて加工していきます。(直接ダウンロードする方法も補足します)
Googleドライブのフォルダにデータを入れる
まず、データを入れるフォルダを作成します。driveの下の「MyDrive」のフォルダに新しいフォルダを作成します。
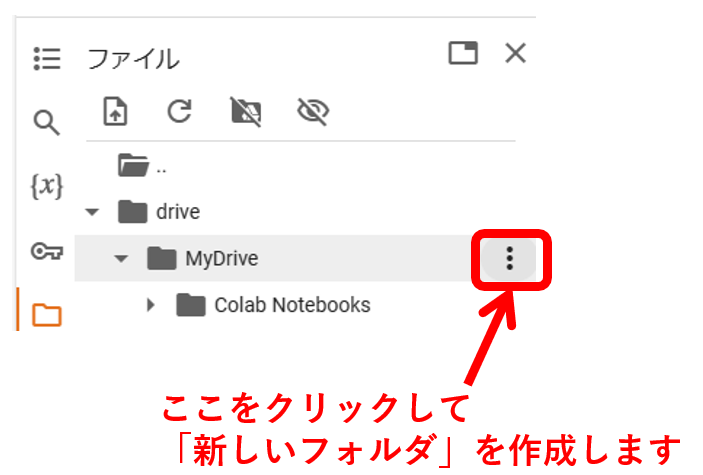
新しいフォルダの名前は「data」としておきましょう。
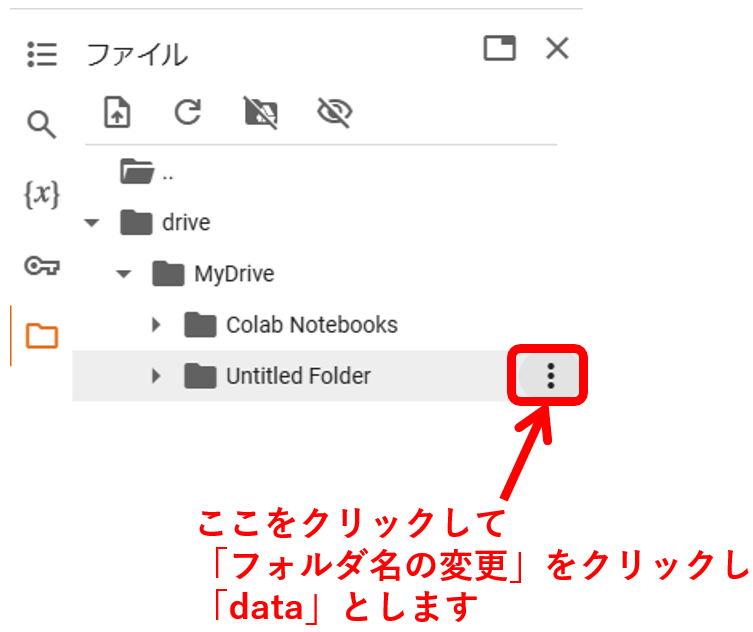
以下のようになりました。
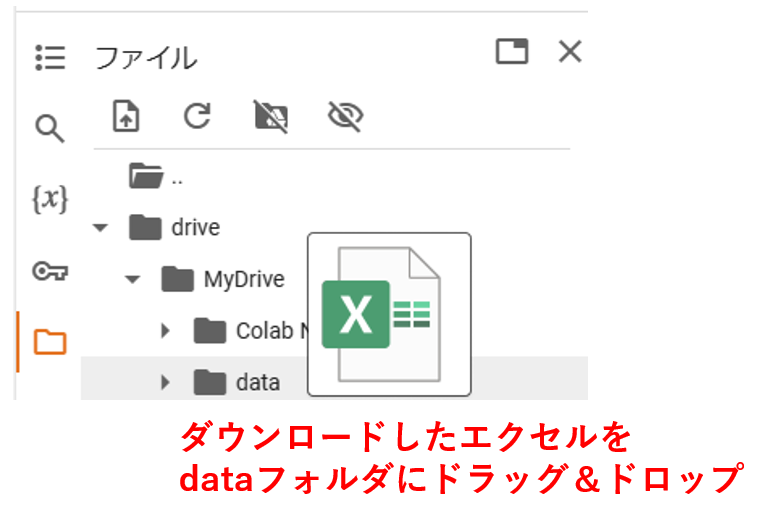
ダウンロードフォルダから、「05k5-1.xlsx」のファイルをdriveの下の「data」にドラッグしていれます。
「ファイルが他の場所に保存されていることをご確認ください」と表示されたら、「OK」をクリックします。

ファイルが「data」に入りました。
Rのパッケージのインストールとパッケージの保存方法
まずはGoogle Colaboratoryの準備をします。
Pythonの以下コードを実行しておきましょう。
# Pythonの分析の準備
import numpy as np
import pandas as pd
import seaborn as sns
pd.options.plotting.backend = "plotly"
import rpy2
import rpy2.robjects as robjects
# Rを使えるようにする
%load_ext rpy2.ipython
# 作業フォルダにlibraryというフォルダを作成します(作業後消えます)
!mkdir library次にRの準備です。
今回は以下の4つのRのパッケージを使いますが、そのままGoogle Colaboratoryでデフォルトで読み込めるものは上2つ(tidyverse, readxl)だけです。実行すると、「パッケージがありません」とエラーがでてしまいます。
# Rの分析の準備
%%R
.libPaths("library") # ライブラリの保存先指定
library(tidyverse)
library(readxl)
library(openxlsx) # ★デフォルトで読み込めないためエラーになる
library(DT) # ★デフォルトで読み込めないためエラーになる以下のコードを実行して、パッケージ4つをインストールします。(5分くらいかかります)
%%R
.libPaths("library") # libraryの保存先フォルダ指定
install.packages("openxlsx")
install.packages("DT")
install.packages("Rcpp") # 前提パッケージ
install.packages("htmlwidgets") # 前提パッケージ
install.packages("crosstalk") # 前提パッケージlibraryのフォルダにインストールできました。
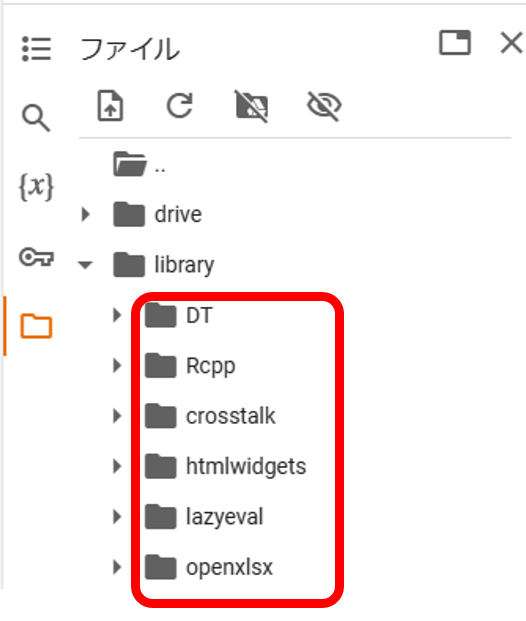
それではRの準備として、あらためて以下コードを実行してみてください。
# Rの分析の準備
%%R
.libPaths("library")
library(tidyverse)
library(readxl)
library(openxlsx)
library(DT)エラーなく終了すれば成功です。
毎回、インストールのために5分も取られるのは時間のムダなので、次回以降は素早く読み込めるように、以下のコードを実行してライブラリの圧縮ファイルを作成しておきましょう。
import tarfile
with tarfile.open('library.tar.gz', 'w:gz') as tar:
tar.add('library')ライブラリの圧縮ファイル「library.tar.gz」ができました。
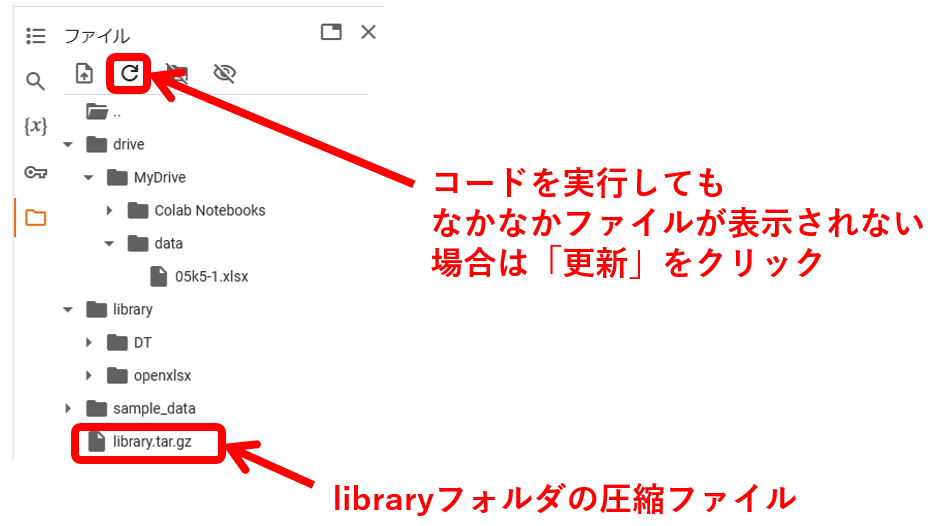
このままでは、作業終了後に消えてしまうので、「library.tar.gz」をdriveの「Colab Notebooks」の
フォルダにドラッグして移動させます。
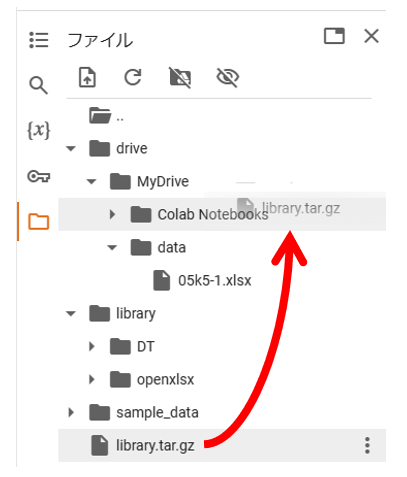
「Colab Notebooks」に移動できました。
次回以降、以下のコードを実行すれば、libraryフォルダが復活し、インストール作業が不要になります。
%%shell
tar xzf "/content/drive/MyDrive/Colab Notebooks/library.tar.gz"【重要】今後も、新たなパッケージをインストールしたら、①圧縮ファイルをつくり、②driveの「Colab Notebooks」に保存するようにしましょう。
Rを使ってデータを閲覧(head, datatable)
では、先ほどダウンロードして保管したエクセルファイル「05k5-1.xlsx」を確認していきましょう。
エクセルファイルの場合、シートが複数ある可能性がありますので、どんなシートが入っているか確認します。以下のコードを実行してみましょう。
%%R
getSheetNames("/content/drive/MyDrive/data/05k5-1.xlsx")
# 直接WEBからダウンロードする場合
# url <- "https://www.e-stat.go.jp/stat-search/file-download?statInfId=000013168601&fileKind=4"
# destfile <- "/content/drive/MyDrive/data/05k5-1.xlsx" # ダウンロードしたファイルの保存先
# download.file(url, destfile)
# Excelファイルのシート名を読み込む
# getSheetNames(destfile)シートが2つ、「2000年~2015年」と「2015年~2020年」があることがわかります。
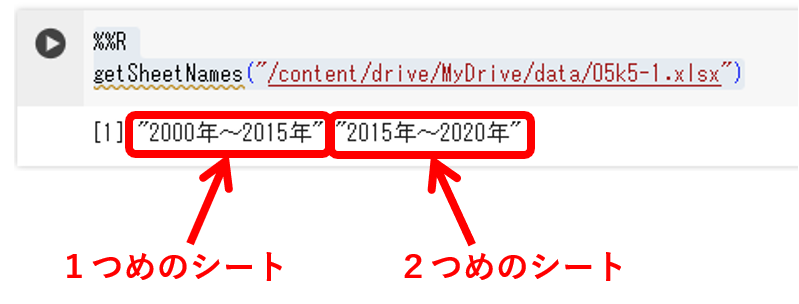
今回は、1つめのシートのデータを取り出して、データを確認していきます。(2つめのシートのデータと合成するやり方はまた次回以降に)
エクセルの1シート目を以下のコードでdfに読み込みます。
%%R
# eStat 政府統計
df <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータの1シート目を読み込む
options(width=100) # データの文字出力の幅を100にする
df %>% # 読み込んだデータをパイプ(%>%)で次の処理につなげる
head(20) # 20行目まで出力するRの記述では、dfのデータフレーム(tibble型)にデータを入れる場合、”<-“を使います。矢印の向きにデータを入れるイメージです。
ちなみに、読み込むシートの指定は番号だけでなく、名前でも指定できます。
%%R
# eStat 政府統計
df <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = "2000年~2015年", col_names = F, skip = 0) # エクセルデータを読み込む
options(width=100) # データの文字出力の幅を100にする
df %>% # 読み込んだデータをパイプ(%>%)で次の処理につなげる
head(20) # 20行目まで出力する実行すると、以下のような出力が返ってきます。
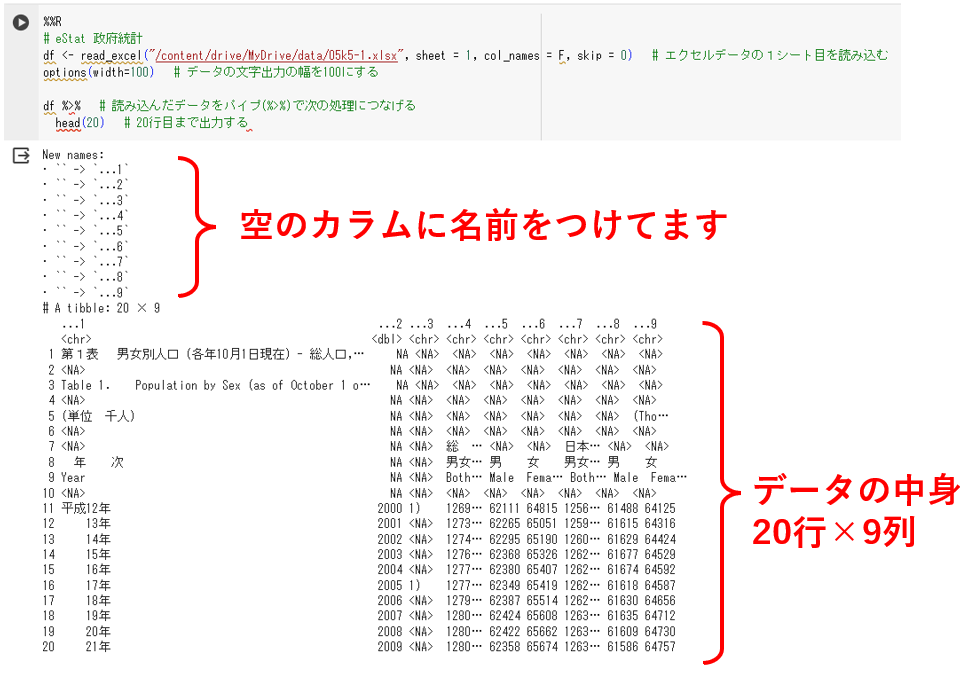
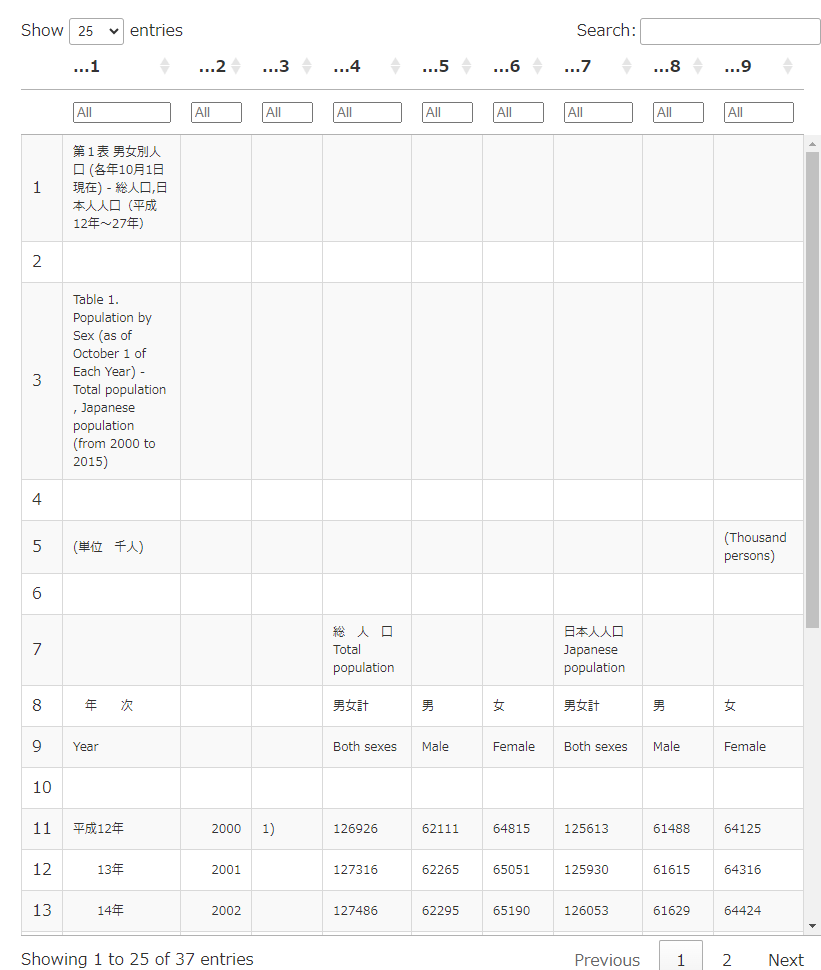
データが途中で切れている部分があって見づらいですね。。
head()で詳細まで確認するのはちょっとキツイです。
どうやら数字の単位は[千人]のようです。単位をメモしつつ、ちゃんとデータが切れないように表示させてみます。
以下コードをそれぞれ、実行してみてください。
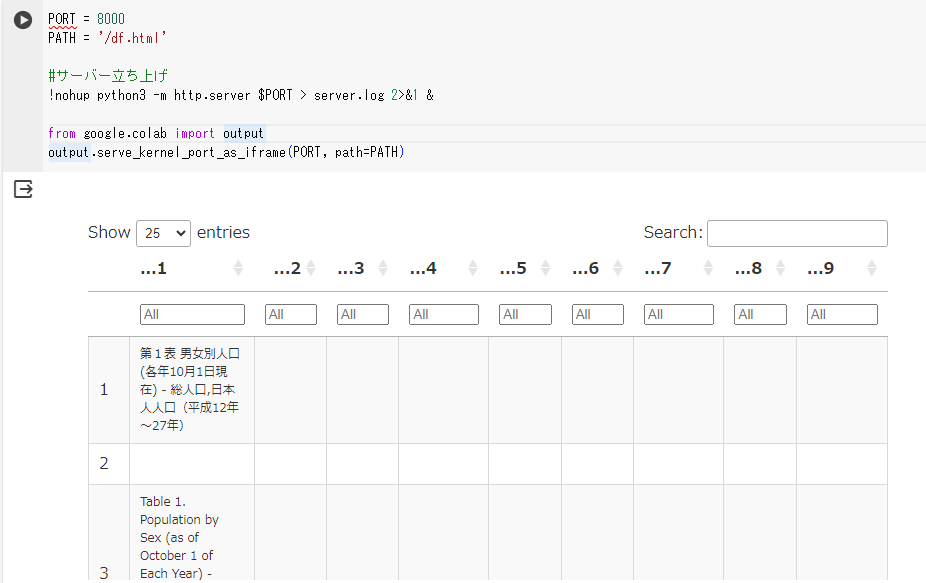
%%R
# データの数字の単位:[千人]
df %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe",
width = 800,
filter = "top",
options = list(pageLength = 25)) %>% # データセットをdatatable()に変換し、パイプ(%>%)で次の処理をつなげる
formatStyle(columns = names(df), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df.html") # ブラウザで読み込むためのdf.htmlのファイルを作成するPORT = 8000
PATH = '/df.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_iframe(PORT, path=PATH)問題なく実行できれば、文字が切れていない表が出てくると思います。
ブラウザの別タブで閲覧したい場合は、以下のコードを実行してみましょう。(Yスクロールを追加します)
%%R
# データセットの数字の単位:[千人]
df %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe",
width = 800,
filter = "top",
options = list(pageLength = 25, scrollY = "800px")) %>% # データセットをdatatable()に変換し、パイプ(%>%)で次の処理をつなげる ★Yスクロール追加
formatStyle(columns = names(df), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df.html") # ブラウザで読み込むためのdf.htmlのファイルを作成するPORT = 8000
PATH = '/df.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH) # ブラウザの別タブで表示実行すると、「df.html」のリンクが出力されるのでクリックして開きます。
df.htmlのイメージです。あんまり扱いやすいデータではなさそうです。
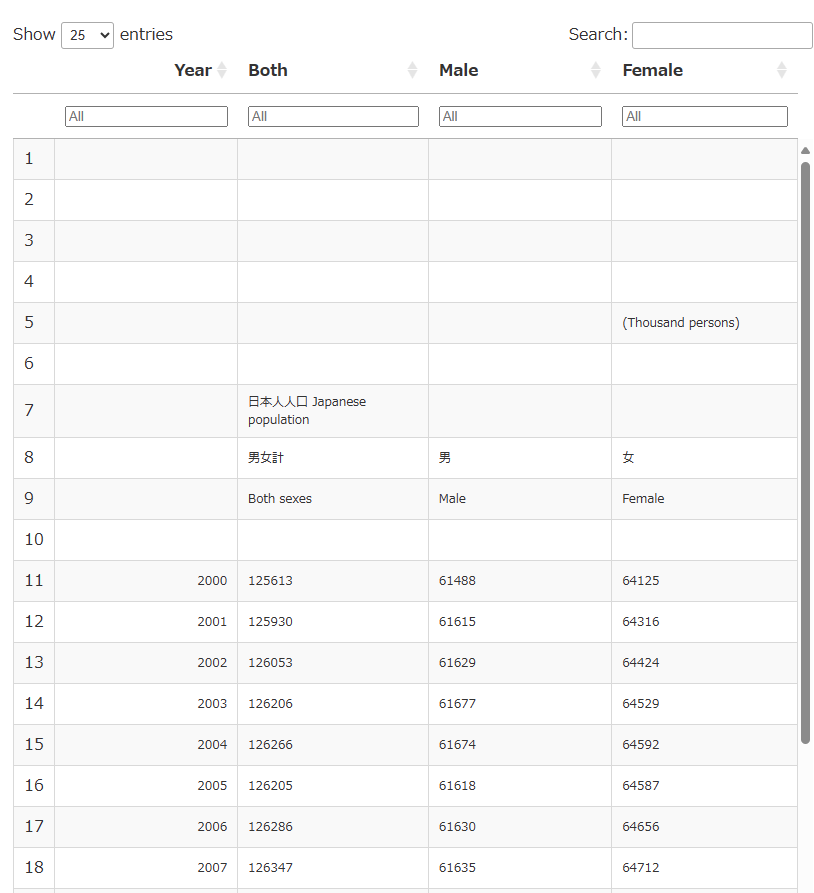
Rを使ってデータを加工
必要な部分のデータを抜き出していきます。
まず縦方向のカラムから。2列目は西暦の年、7列目は日本人の人口(男女計)、8列目は男、9列目は女の人口のデータになっているようです。以下のコードで、カラムに名前をつけて出力してみましょう。
%%R
# あらためてデータを読み込む(理由:selectでカラムの縦の列を削除するので、以降修正してもいいように)
df <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータを読み込む
df <- df %>%
rename("Year" = 2, "Both" = 7, "Male" = 8, "Female" = 9) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) # カラムを選択(Year, Both, Male, Femaleだけにする)
df %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe",
width = 800,
filter = "top",
options = list(pageLength = 25, scrollY = "800px")) %>% # データセットをdatatable()に変換し、パイプ(%>%)で次の処理をつなげる ★Yスクロールバー追加
formatStyle(columns = names(df), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df.html") # ブラウザで読み込むためのdf.htmlのファイルを作成するPORT = 8000
PATH = '/df.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH) # ブラウザの別タブで表示横方向はスッキリしました。
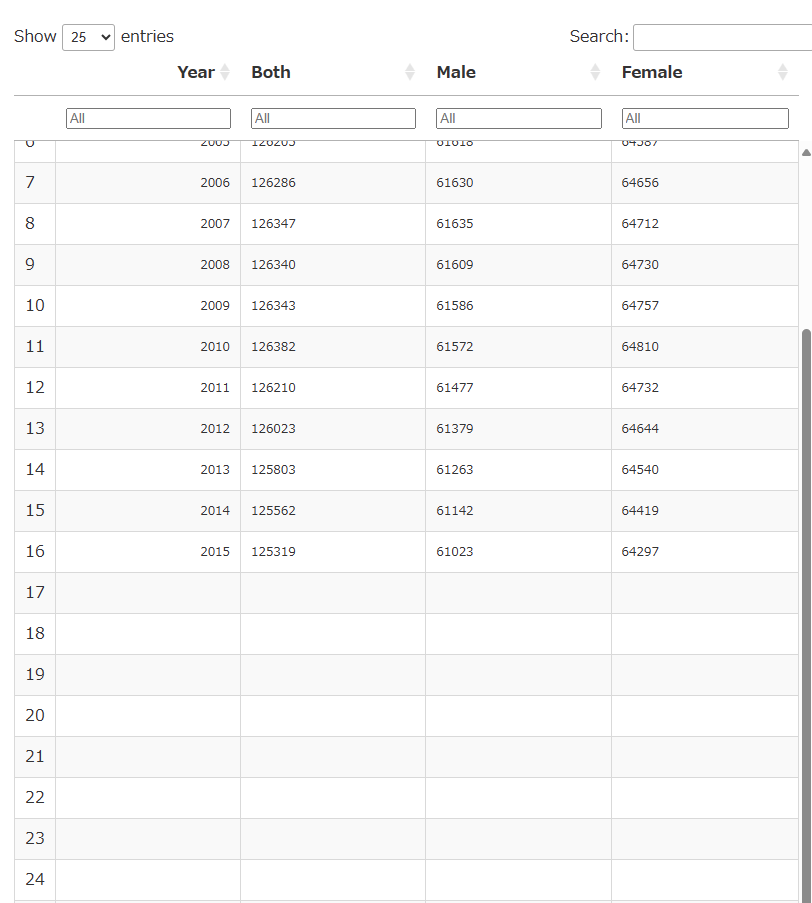
次に先頭のいらない10行をslice()で削除します。
slice(-c(1:10))のc(1:10)の意味は、Combine Valuesのcで、1~10までの数字ベクトル、つまり1~10行目までを指定していて、-(マイナス)がつくことで、削除する意味になります。
%%R
# あらためてデータを読み込む(理由:select、sliceで列、行を削除するので、以降修正してもいいように)
df <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータを読み込む
df <- df %>%
rename("Year" = 2, "Both" = 7, "Male" = 8, "Female" = 9) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) %>% # カラム(列)を選択(Year, Both, Male, Femaleだけにする)し、パイプ(%>%)で次の処理につなげる
slice(-c(1:10)) # ロー(行)の先頭のいらない部分を削除
df %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe",
width = 800,
filter = "top",
options = list(pageLength = 25, scrollY = "800px")) %>% # データセットをdatatable()に変換し、パイプ(%>%)で次の処理をつなげる ★Yスクロールバー追加
formatStyle(columns = names(df), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df.html") # ブラウザで読み込むためのdf.htmlのファイルを作成するPORT = 8000
PATH = '/df.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH) # ブラウザの別タブで表示先頭のごちゃごちゃも消えてイイ感じと思いきや、末尾には何もデータがない行がたくさんある。
データをslice()で、今度はslice(c(1:16))として、-(マイナス)がありません。
この場合、1~16行目までを残す、ことになります。
%%R
# あらためてデータを読み込む(理由:select、sliceで列、行を削除するので、以降修正してもいいように)
df <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータを読み込む
df <- df %>%
rename("Year" = 2, "Both" = 7, "Male" = 8, "Female" = 9) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) %>% # カラム(列)を選択(Year, Both, Male, Femaleだけにする)し、パイプ(%>%)で次の処理につなげる
slice(-c(1:10)) %>% # ロー(行)の先頭のいらない部分を削除し、パイプ(%>%)で次の処理につなげる
slice(c(1:16)) # ロー(行)の1~16行目までを抽出する
df %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe",
width = 800,
filter = "top",
options = list(pageLength = 25)) %>% # データセットをdatatable()に変換し、パイプ(%>%)で次の処理をつなげる ★Yスクロールバー追加
formatStyle(columns = names(df), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df.html") # ブラウザで読み込むためのdf.htmlのファイルを作成するPORT = 8000
PATH = '/df.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH) # ブラウザの別タブで表示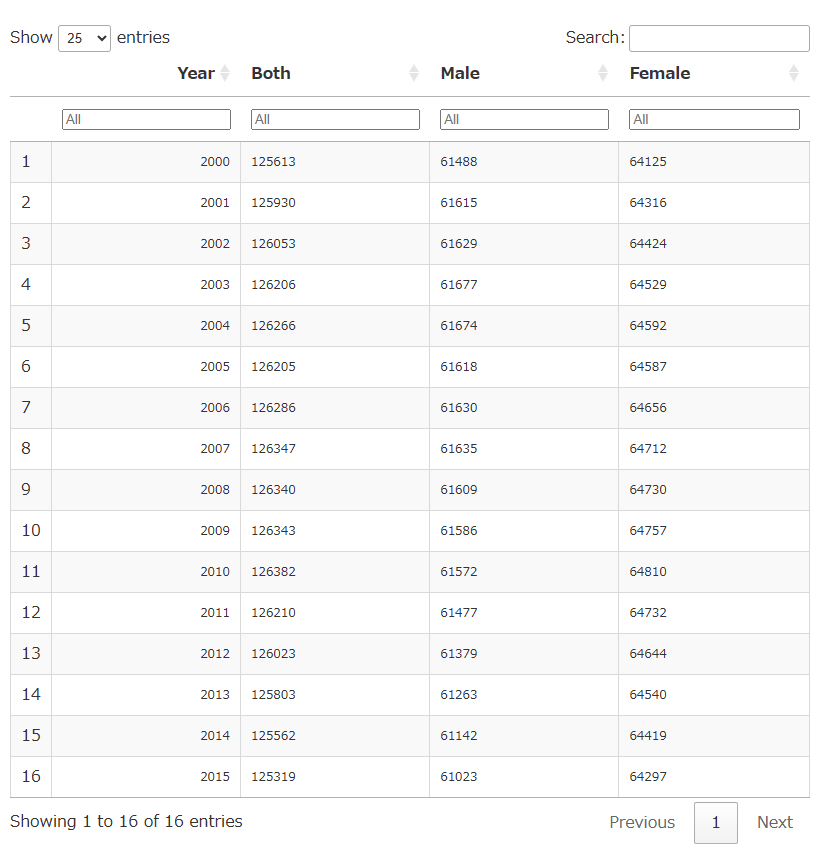
うまく抜き出せました。あらためて出力してみます。
%%R
df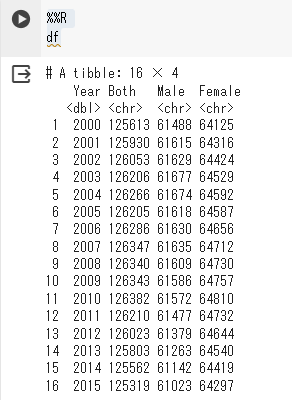
むむ? Both、Male、Femaleがchr(character型:文字列型)になってる。
以下のコードで確認できます。
※sapply(class)は各列に対してclass:型の確認をしなさい、というコードです。
%%R
# データ型の確認
df %>% sapply(class)やっぱり、character型になってる。このままではグラフがうまくつくれないので、数字として扱うためにデータ型を変更します。

以下コードで、数字型(numeric型)に変更します。(列番号指定)
%%R
# 型(class)をnumeric型に変更する(その1)
df[, c(1,2,3,4)] <- lapply(df[, c(1,2,3,4)], as.numeric)
df %>% sapply(class)または(カラムの列名で指定)
%%R
# 型(class)をnumeric型に変更する(その2)
df[, c("Year","Both","Male","Female")] <-
lapply(df[, c("Year","Both","Male","Female")], as.numeric)
df %>% sapply(class)数字型に変更できました。

動作確認のために、棒グラフをつくってみます。(次回以降、グラフの細かい説明や修正をやっていきますので今回はとりあえずの確認です)
%%R
# とりあえずの棒グラフ
df %>%
ggplot(aes(x=Year, y=Both))+
geom_bar(stat="identity", fill="lightblue")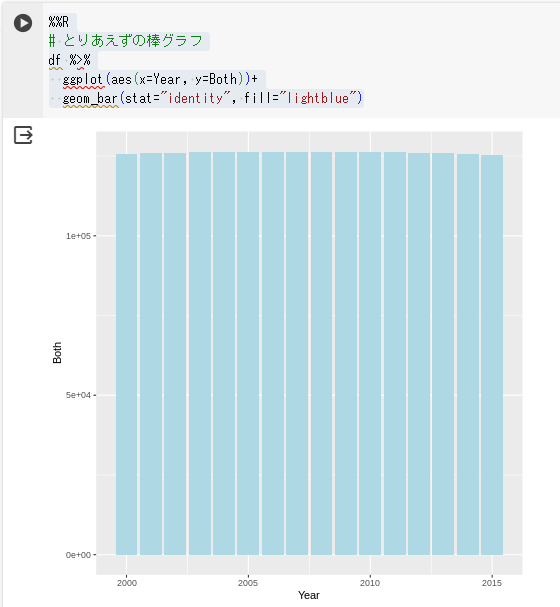
加工したデータをRからPythonへ、PythonからRへ受け渡す方法
最後に、Rで作成したdfのデータをPythonに渡す方法と、PythonのデータをRに渡す方法をご紹介します。
■PythonからRのデータを読み込んで出力する
# PythonからRのデータを読み込む
df_py = robjects.r("df")
print(df_py)
■RにPythonのデータを渡し、Rで出力する
%R -i df_py # Python側のデータフレームをRにインポート%%R
df_py
以上、エクセルデータをRで読み込み、加工して、Pythonとデータを出し入れする方法でした。
次回以降、もう少しパッケージを増やしつつ、グラフ作成や集計方法をやっていこうと思います。
お疲れさまでした。

