
以前、eStatの政府統計データから人口データを使って、データ加工を取り上げましたが、今回はその続きになります。今回は過去1950年から2020年までの人口データを加工して合成し、グラフ作成まで連続して一気にやってみます。(重複する部分もありますが、説明は短縮して振り返りながらいきます)
本日のメニュー:データ加工とグラフ作成のケーススタディ
ゴールイメージ
今回は内容のボリュームがあるので、最初にどんなものを出力するか、ゴールイメージを先にお見せします。
綺麗なクロス集計(Year、Populationの平均値と標準偏差だす意味ないですけど。。)

ggplotとplotlyのグラフ
では、いつもどおり、ドライブのマウントから。
Google Colaboratoryの準備(ドライブのマウント)
最初にGoogleドライブと連携できるようにします。Google Colaboratoryで作業するフォルダは作業が終わるとコード以外は消えてしまうので、データは消されない場所に入れます。
まずはGoogle Colaboratoryにログインしましょう。
ファイルから「ノートブックの新規作成」をクリック。
ファイル名は適当につけます。(ここでは「R_Python_linkage.ipynb」とします)
以下のフォルダのアイコンをクリックします。
以下をクリックします。
「Googleドライブのファイルへのアクセスを許可しますか?」と表示されたら、「Googleドライブに接続」をクリックします。

はじめての場合は、以下のようなコードが出現するので、▶をクリックして実行します。
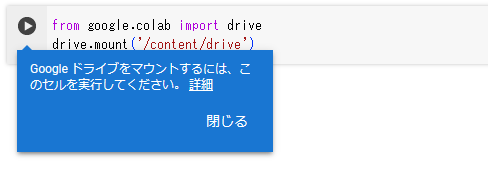
アクセスできる情報は「すべて選択」を選択して、「続行」をクリックします。
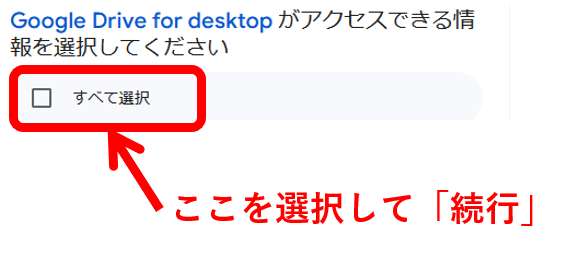
以下のように「drive」が出てきたら、Googleドライブのマウントができています。
オープンデータのダウンロード(eStat 政府統計データ)
今回は、eStatの政府統計データを使って、データ加工を実践してみます。
まず、以下のURLにある、「男女別人口(各年10月1日現在)- 総人口、日本人人口(2000年~2020年)」をダウンロードします。
人口推計 長期時系列データ 長期時系列データ(平成12年~令和2年) | ファイル | 統計データを探す | 政府統計の総合窓口 (e-stat.go.jp)
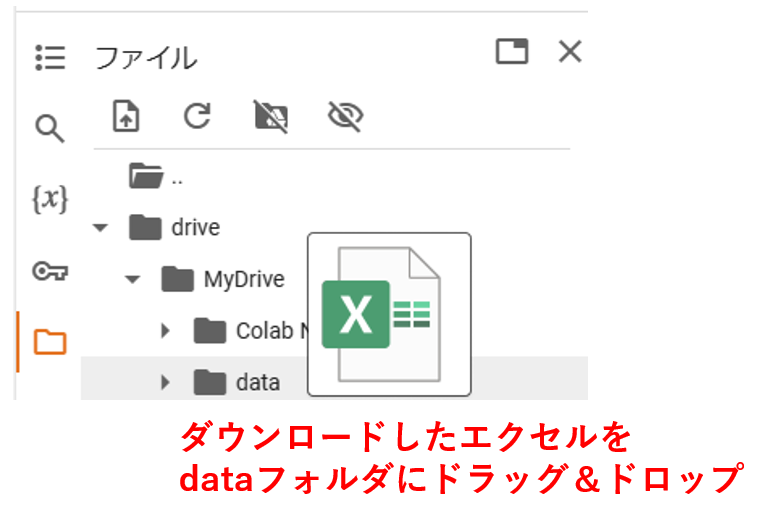
「05k5-1.xlsx」というファイルがダウンロードされます。今回は、このデータをdriveに入れて加工していきます。(直接ダウンロードする方法も補足します)
Googleドライブのフォルダにデータを入れる
まず、データを入れるフォルダを作成します。driveの下の「MyDrive」のフォルダに新しいフォルダを作成します。
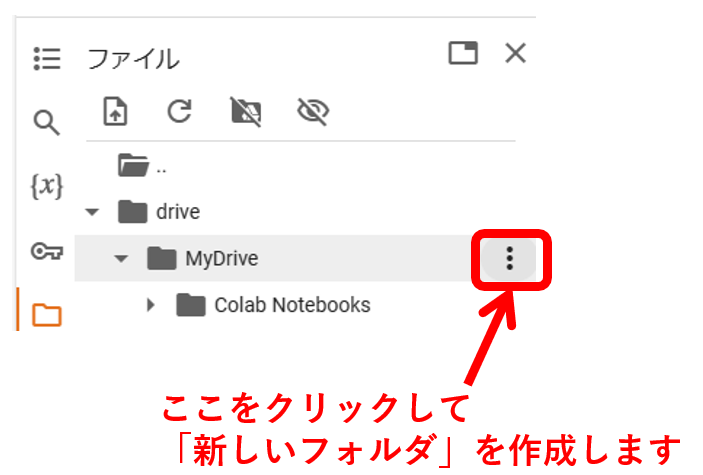
新しいフォルダの名前は「data」としておきましょう。
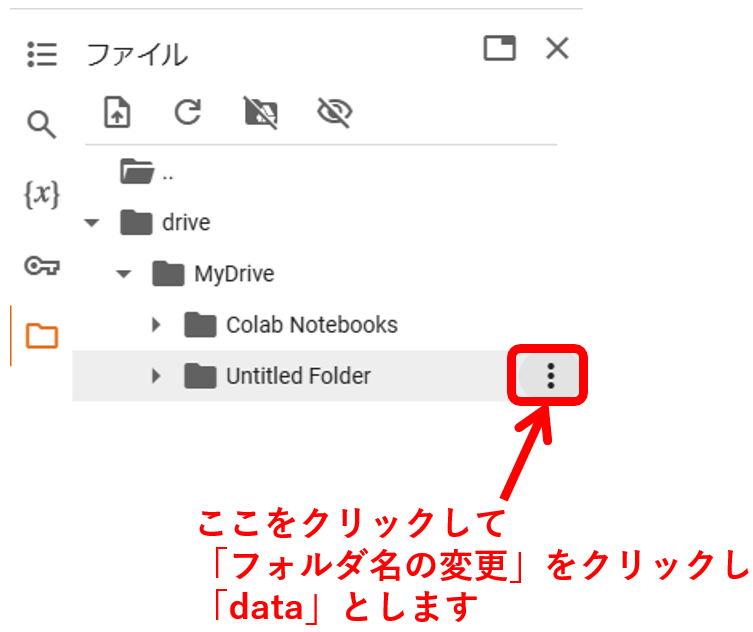
以下のようになりました。
ダウンロードフォルダから、「05k5-1.xlsx」のファイルをdriveの下の「data」にドラッグしていれます。
「ファイルが他の場所に保存されていることをご確認ください」と表示されたら、「OK」をクリックします。

ファイルが「data」に入りました。
Rのインストール済みパッケージの復活(libraryフォルダ)
以下のコードでlibraryフォルダを復活させます。
%%shell
# Colab Notebooksのフォルダにlibrary.tar.gzを保存しておいた場合、インストールしたパッケージの復活
tar xzf "/content/drive/MyDrive/Colab Notebooks/library.tar.gz"準備
いつもの準備作業いきます。今回はRのグラフの日本語化ショートカットバージョンです。まだ日本語化をしたことがない場合は、前回紹介したフォントの導入からやりましょう。
では準備作業いきます。
# Pythonの分析の準備
import numpy as np
import pandas as pd
import seaborn as sns
pd.options.plotting.backend = "plotly"
import rpy2
import rpy2.robjects as robjects
# Rを使えるようにする
%load_ext rpy2.ipython今回使う、新しいRのパッケージをインストールして、libraryフォルダを圧縮保存しておきます。
# パッケージを保存していない場合、コメント(#)を外してインストール(少し時間かかります)
%%R
.libPaths("library") # libraryの保存先フォルダ指定
# install.packages("openxlsx") # エクセル、シート名読み込み
# install.packages("DT") # インタラクティブな集計表
# install.packages("Rcpp")
# install.packages("htmlwidgets")
# install.packages("crosstalk")
# install.packages("extrafont")
# install.packages("systemfonts")
install.packages("gt") # 綺麗なクロス集計表出力
install.packages("gtsummary") # 綺麗なサマリークロス集計表出力
install.packages("RCurl") # HTTPリクエストを作成
install.packages("plotly") # インタラクティブなグラフ作成# 新規にRのパッケージをインストールした場合、圧縮保管しているパッケージを上書き保存
import tarfile
with tarfile.open('/content/drive/MyDrive/Colab Notebooks/library.tar.gz', 'w:gz') as tar:
tar.add('library')Rのパッケージを読み込みます。
# Rの分析の準備
# パッケージがないとエラーが出る場合は、戻って必要なパッケージをインストールする
%%R
.libPaths("library") # libraryの保存先フォルダ指定
library(tidyverse) # デフォルトパッケージ
library(readxl) # デフォルトパッケージ エクセル読み込み(高速のtibble型)
library(extrafont) # フォントの設定
library(systemfonts)
library(openxlsx) # エクセル、シート名読み込み
library(DT) # インタラクティブな集計表
library(gt) # 綺麗なクロス集計表出力
library(gtsummary) # 綺麗なサマリークロス集計表出力
library(RCurl) # HTTPリクエストを作成
library(plotly) # インタラクティブなグラフ作成
library(RColorBrewer) #カラーパレット# フォント確認
%%R
fonts()%%R
system("apt-get install -y fonts-noto-cjk", intern=TRUE)いったん、再起動して(日本語フォント対応)
exit()数秒待ってから、あらためて以下、準備作業を実行
# Pythonの分析の準備
import numpy as np
import pandas as pd
import seaborn as sns
pd.options.plotting.backend = "plotly"
import rpy2
import rpy2.robjects as robjects
# Rを使えるようにする
%load_ext rpy2.ipython# Rの分析の準備
# パッケージがないとエラーが出る場合は、戻って必要なパッケージをインストールする
%%R
.libPaths("library") # libraryの保存先フォルダ指定
library(tidyverse) # デフォルトパッケージ
library(readxl) # デフォルトパッケージ エクセル読み込み(高速のtibble型)
library(extrafont) # フォントの設定
library(systemfonts)
library(openxlsx) # エクセル、シート名読み込み
library(DT) # インタラクティブな集計表
library(gt) # 綺麗なクロス集計表出力
library(gtsummary) # 綺麗なサマリークロス集計表出力
library(RCurl) # HTTPリクエストを作成
library(plotly) # インタラクティブなグラフ作成
library(RColorBrewer) #カラーパレットeStat 政府統計データの読み込み
前回、政府統計データをダウンロードして保存しているならコードへ。保存していなければ、以下、以前のページで政府統計データのダウンロード、ドライブへの入れ方を説明しています。
# eStat 政府統計の人口データ
# https://www.e-stat.go.jp/stat-search/file-download?statInfId=000013168601&fileKind=4
%%R
# /content/drive/MyDrive/data にフォルダを作成してダウンロードした"05k5-1.xlsx"を入れておいた場合
getSheetNames("/content/drive/MyDrive/data/05k5-1.xlsx")
# 直接WEBからダウンロードする場合
# url <- "https://www.e-stat.go.jp/stat-search/file-download?statInfId=000013168601&fileKind=4"
# destfile <- "/content/drive/MyDrive/data/05k5-1.xlsx" # ダウンロードしたファイルの保存先
# download.file(url, destfile)
# Excelファイルのシート名を読み込む
# getSheetNames(destfile)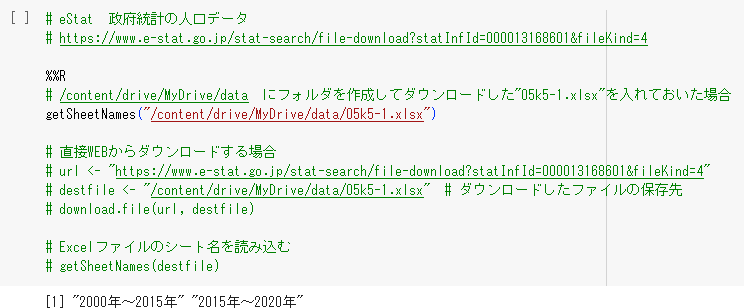
1950~2000年までの古いデータもダウンロードします。今度は直接ダウンロードしてみます。
# eStat 政府統計の人口データ(旧) 1950年からの古いデータも読み込む
# https://www.e-stat.go.jp/stat-search/file-download?statInfId=000000090261&fileKind=0
%%R
# 直接WEBからダウンロードする場合
url <- "https://www.e-stat.go.jp/stat-search/file-download?statInfId=000000090261&fileKind=0"
destfile <- "/content/drive/MyDrive/data/old_05k5-1.xlsx" # ダウンロードしたファイルの保存先
download.file(url, destfile)
# Excelファイルのシート名を読み込む
getSheetNames(destfile)%%R
# eStat 政府統計
df1 <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータの1シート目を読み込む
options(width=100) # データの文字出力の幅を100にする
df1 %>% # 読み込んだデータをパイプ(%>%)で次の処理につなげる
head(20) # 20行目まで出力するデータをブラウザで閲覧するため、datatable()の出力をdf.htmlに保存します。
%%R
# データセットの数字の単位:[千人]
df1 %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, # Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df1), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df1.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df1.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_iframe(PORT, path=PATH)# ブラウザの別タブで表示
PORT = 8000
PATH = '/df1.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)次に進みます。(以前と重複する部分なのでサクサクいきます)
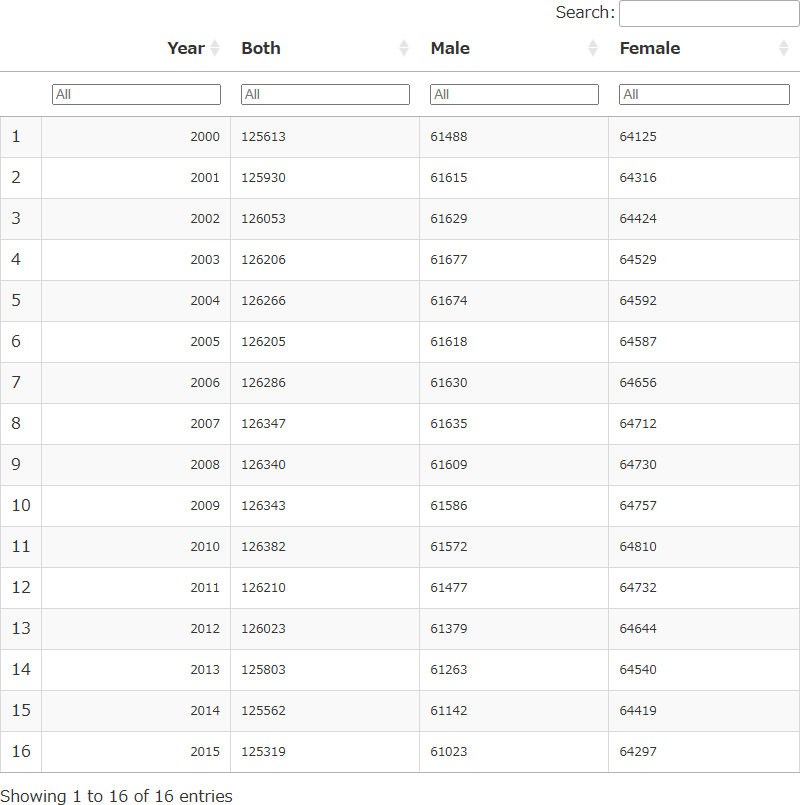
%%R
# データセットの数字の単位:[千人]
# あらためてデータを読み込む(理由:select、sliceで列、行を削除するので、以降修正してもいいように)
df1 <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータを読み込む
df1_slice <- df1 %>%
rename("Year" = 2, "Both" = 7, "Male" = 8, "Female" = 9) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) %>% # カラム(列)を選択(Year, Both, Male, Femaleだけにする)し、パイプ(%>%)で次の処理につなげる
slice(-c(1:10)) %>% # ロー(行)の先頭のいらない部分を削除し、パイプ(%>%)で次の処理につなげる
slice(c(1:16)) # ロー(行)の1~16行目までを抽出する
df1_slice %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, #Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df1_slice), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df1_slice.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df1_slice.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)sheetの1枚目を綺麗に抜き出せました。
同様にsheetの2枚目をやっていきます。(行と列のフォーマットが違ったのであらためて)
# エクセルの2シート目も同様に読み込む
%%R
# データセットの数字の単位:[千人]
df2 <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 2, col_names = F, skip = 0) # エクセルデータを読み込む
df2 %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, #Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df2), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df2.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df2.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_iframe(PORT, path=PATH)必要な部分を抜き出していきます。
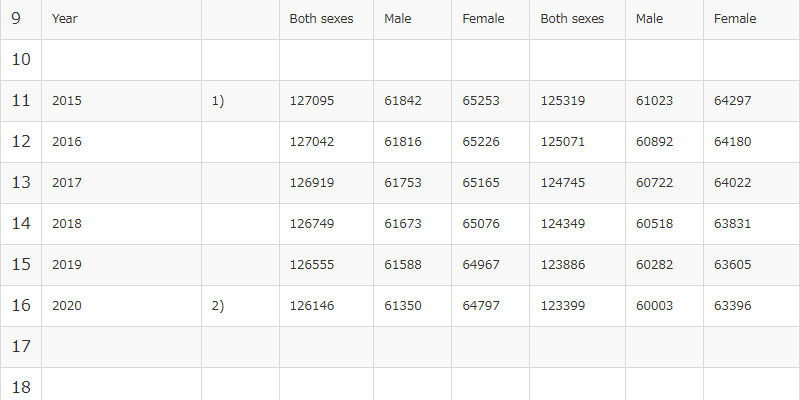
%%R
# データセットの数字の単位:[千人]
# あらためてデータを読み込む(理由:select、sliceで列、行を削除するので、以降修正してもいいように)
df2 <- read_excel("/content/drive/MyDrive/data/05k5-1.xlsx", sheet = 2, col_names = F, skip = 0) # エクセルデータを読み込む
df2_slice <- df2 %>%
rename("Year" = 1, "Both" = 6, "Male" = 7, "Female" = 8) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) %>% # カラム(列)を選択(Year, Both, Male, Femaleだけにする)し、パイプ(%>%)で次の処理につなげる
slice(-c(1:10)) %>% # ロー(行)の先頭のいらない部分を削除し、パイプ(%>%)で次の処理につなげる
slice(c(1:6)) # ロー(行)の1~16行目までを抽出する
df2_slice %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, # Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df2_slice), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df2_slice.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df2_slice.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)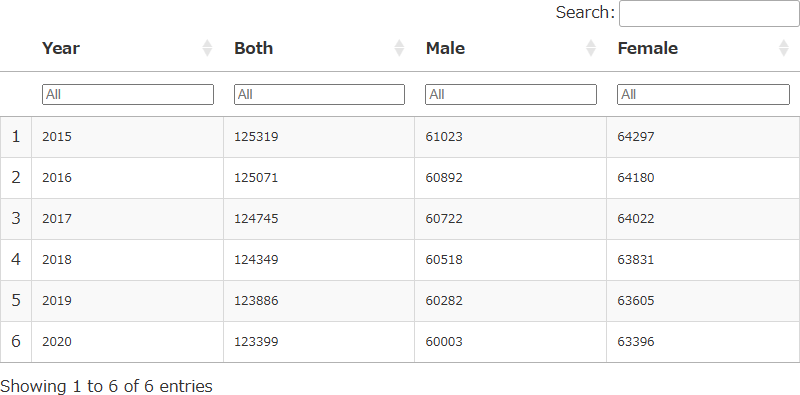
さらに1950~2000年までの古いデータもダウンロードして同様に加工します。
%%R
# eStat 政府統計 旧データ1920~2000年
df_old <- read_excel("/content/drive/MyDrive/data/old_05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータの1シート目を読み込む
options(width=100) # データの文字出力の幅を100にする
df_old %>% # 読み込んだデータをパイプ(%>%)で次の処理につなげる
head(20) # 20行目まで出力する%%R
# データセットの数字の単位:[千人]
df_old %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, #Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df_old), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df_old.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df_old.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)日本人の集計は1950年からのようです。(左端3列、41行目からデータがある)
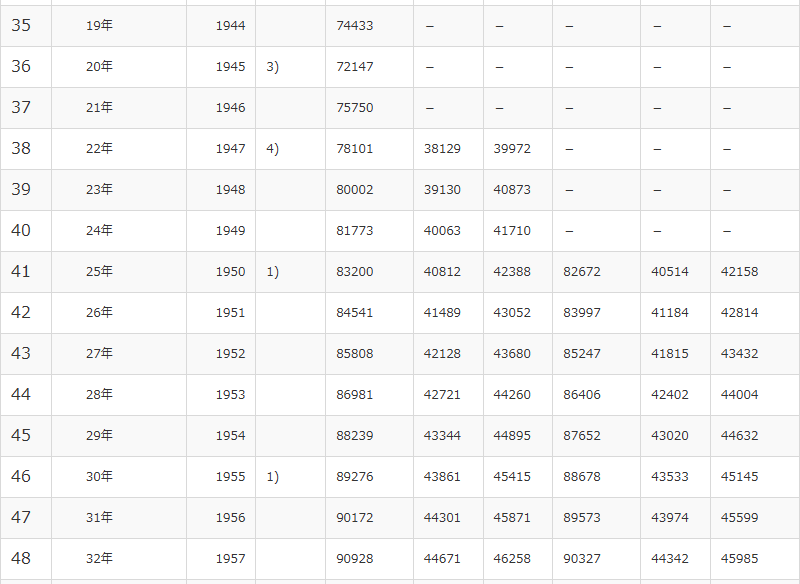
%%R
# データセットの数字の単位:[千人]
# あらためてデータを読み込む(理由:select、sliceで列、行を削除するので、以降修正してもいいように)
df_old <- read_excel("/content/drive/MyDrive/data/old_05k5-1.xlsx", sheet = 1, col_names = F, skip = 0) # エクセルデータを読み込む
df_old_slice <- df_old %>%
rename("Year" = 2, "Both" = 7, "Male" = 8, "Female" = 9) %>% # カラム(列)の名前を変えて、パイプ(%>%)で次の処理につなげる
select(Year, Both, Male, Female) %>% # カラム(列)を選択(Year, Both, Male, Femaleだけにする)し、パイプ(%>%)で次の処理につなげる
slice(-c(1:40)) %>% # ロー(行)の先頭のいらない部分を削除し、パイプ(%>%)で次の処理につなげる
slice(c(1:51)) # ロー(行)の1~16行目までを抽出する
df_old_slice %>% # データセットをパイプ(%>%)で次の処理につなげる
datatable(class = "cell-border stripe", # データセットをdatatable()に変換
width = 800, # 幅を800に指定
filter = "top",
options = list(pageLength = 25, # paging = Tにしたとき、出力する初期の行数
#scrollY = 400, #Yスクロール追加したい場合
paging = F) # paging=Fでページを分けて表示しない、paging=Tでページに分けて表示
) %>% # パイプ(%>%)で次の処理につなげる
formatStyle(columns = names(df_old_slice), `font-size` = "12px") %>% # 文字サイズを12pxにして、パイプ(%>%)で次の処理をつなげる
saveWidget("df_old_slice.html") # ブラウザで読み込むためのhtmlのファイルを作成するPORT = 8000
PATH = '/df_old_slice.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)1950~2000年までの古いデータも抜き出せました。
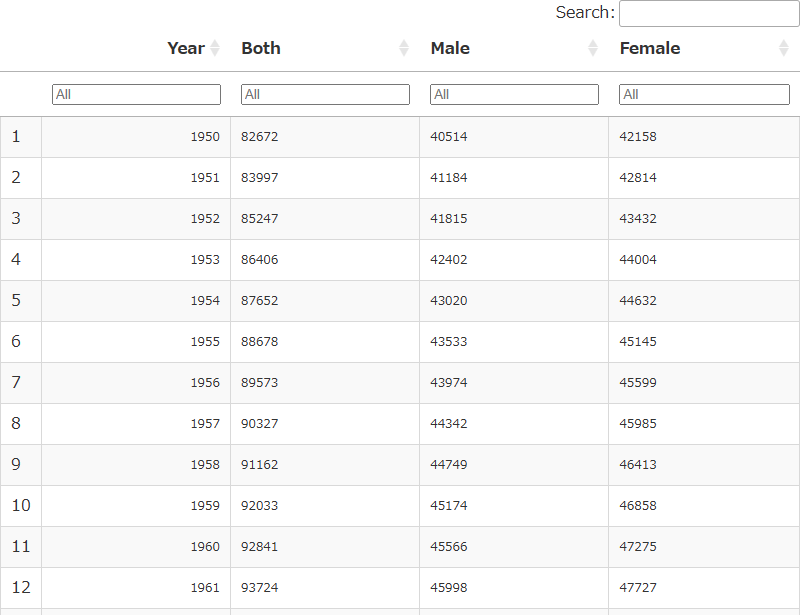
読み込んで抜き出した3つのデータを合成
2000~2015年までのデータdf1_slice と 2015~2020年までのデータdf2_slice、さらに1950~2000年までのデータdf_old_slice を合成します。(2015と2020は重複しているので合成)
%%R
df1_slice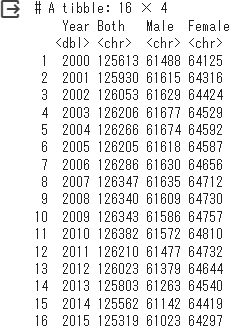
%%R
df2_slice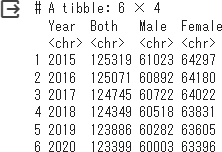
%%R
df_old_slice %>% tail(10) # 最後の10行を出力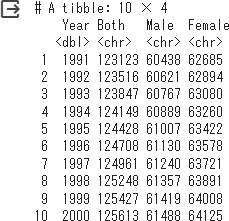
# df1_sliceとdf2_slice、df_old_sliceをマージする
# 2015年、2020年は重複しているがマージによって、1つにまとめる
%%R
df <- merge(df1_slice, df2_slice, all=T) # df1_sliceとdf2_sliceを合成
df <- merge(df, df_old_slice, all=T) # df_old_sliceも合成
# 型(class)をnumeric型に変更する(方法その1:カラム番号指定)
df[, c(1,2,3,4)] <- lapply(df[, c(1,2,3,4)], as.numeric)
df %>% sapply(class)
# 型(class)をnumeric型に変更する(方法その2:カラム名指定)
df[, c("Year","Both","Male","Female")] <-
lapply(df[, c("Year","Both","Male","Female")], as.numeric)
df %>% sapply(class)データはすべて整数の型(numeric)にしています。

以下コードでデータを出力すると、2015、2020も1つになっていることが確認できます。
# dfを出力
%%R
df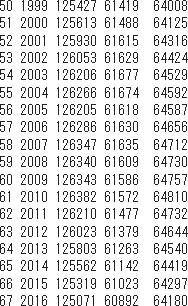
合成したデータをロングデータに変換する
グラフで色分けしやすいようにBoth,Male,Femaleのカラムを新しいカラムGenderとして圧縮させます。(Genderにはカテゴリ変数としてBoth,Male,Femaleの文字が入り、新しいカラムPopulationには人口データの数字が入ります)
# X軸をYear、Y軸をGenderとして縦型のロングデータに変換
# Genderは、Both、Male、Femaleのカテゴリ変数とする
# keyをカテゴリ変数のGenderとし、valueの人数はPopulationとする
%%R
df_long <- df %>% # df_longのデータテーブルを新規作成、dfのデータに対し、パイプ(%>%)で次の処理につなげる
gather(key = Gender, value = Population, -Year) # -YearでYaerを除くカラムをカテゴリ変数Genderとし、人口データをPopulationとする
df_long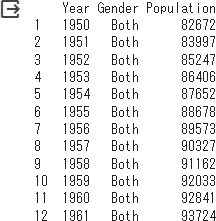
綺麗なクロス集計表 gtとgtsummary(そのまま資料に使えるレベル)
gtsummaryで綺麗なクロス集計をサクッとつくってみましょう。
gtは多分グランドトータルのこと。いろいろ工夫して自分好みにできるのでリンク貼っておきます。
Easily Create Presentation-Ready Display Tables • gt (rstudio.com)
%%R
theme_gtsummary_mean_sd() # gtsummaryを平均値と標準偏差にする
# reset_gtsummary_theme() # gtsummaryを中央値(median)と四分位範囲(IQR)に戻す
gt_tbl <- tbl_summary(df_long) %>% as_gt() # as_gt()でgtクロス集計フォーマットに変換
gt::gtsave(gt_tbl, "df_summary.html")PORT = 8000
PATH = '/df_summary.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)出力結果。
綺麗なクロス集計だけど、YearやPopulationの平均値と標準偏差だしても意味ないですけど。。
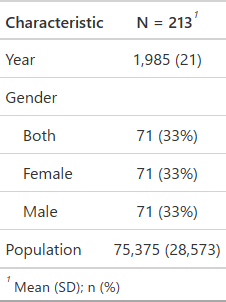
以下のように、 by = Gender を追記すると、Both,Male,Femaleで分けてくれます。
%%R
theme_gtsummary_mean_sd() # gtsummaryを平均値と標準偏差にする
# reset_gtsummary_theme() # gtsummaryを中央値(median)と四分位範囲(IQR)に戻す
gt_tbl <- tbl_summary(df_long, by = Gender) %>% as_gt() # as_gt()でgtクロス集計フォーマットに変換
gt::gtsave(gt_tbl, "df_summary.html")出力結果。(YearとPopulationの平均値と標準偏差だしても意味ないですけど。。)

綺麗なクロス集計が、お好みで作れるように同じような集計をgtを使って手動でやってみます。
# GTパッケージを使って、マニュアルで同じような綺麗なクロス集計表をつくる
%%R
gt_manual <- df_long %>% # df_longのロングデータをパイプ(%>%)でつなげて次の処理へ
group_by(Gender) %>% # Genderをグループとして指定
summarise(n=n(), 平均値=round(mean(Population),1), 中央値=round(median(Population),1), 標準偏差=round(sd(Population),1)) %>% # summariseでn数、平均値、中央値、標準偏差を出力
gt() %>% # gt()で綺麗なクロス集計に変換
cols_align(align = "right") # 右寄せ
gt::gtsave(gt_manual, "df_summary_manual.html")PORT = 8000
PATH = '/df_summary_manual.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)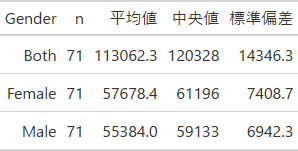
Rのggplotでバーグラフ作成
このデータでバーグラフを作成してみましょう。
グラフ作成の参考にhead()で6行だけ出力しておきます。
%%R
df_long %>% head()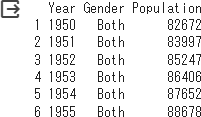
# ggplotでとりあえずの棒グラフ作成
%%R
p <- df_long %>%
filter(Gender != "Both") %>%
ggplot(aes(x = Year, y = Population, fill = Gender)) + # ggplotのコード連結は"+"を使う
geom_bar(stat="identity")
pあまりにも「とりあえず」過ぎるグラフの完成。。
見た目が悪いので修正していきます。
まずカラーパレットから選択していきます。
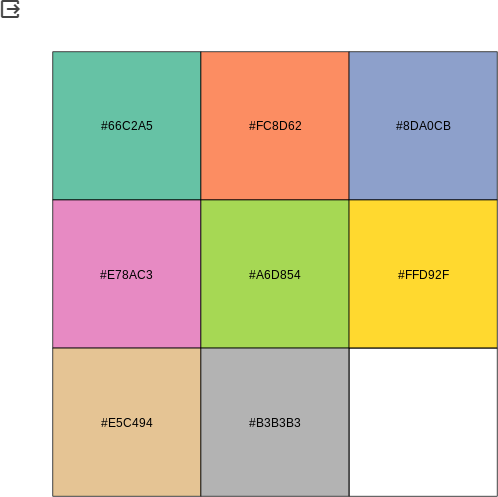
# カラーパレットの指定
%%R
display.brewer.all() # カラーパレット一覧
colors <- brewer.pal(8, "Set2") # Set2から8色すべて読み込み
scales::show_col(colors) # colorsに入れた色の一覧を表示(左上から右に1,2,3,・・・)
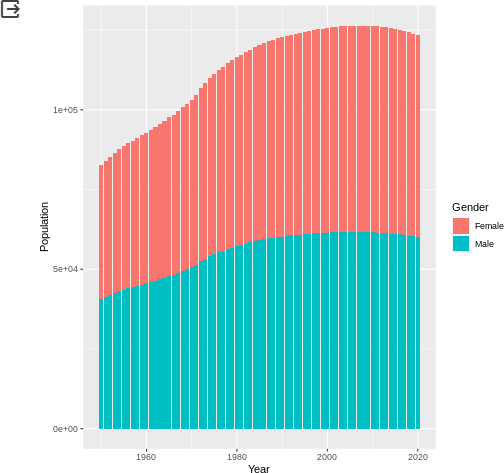
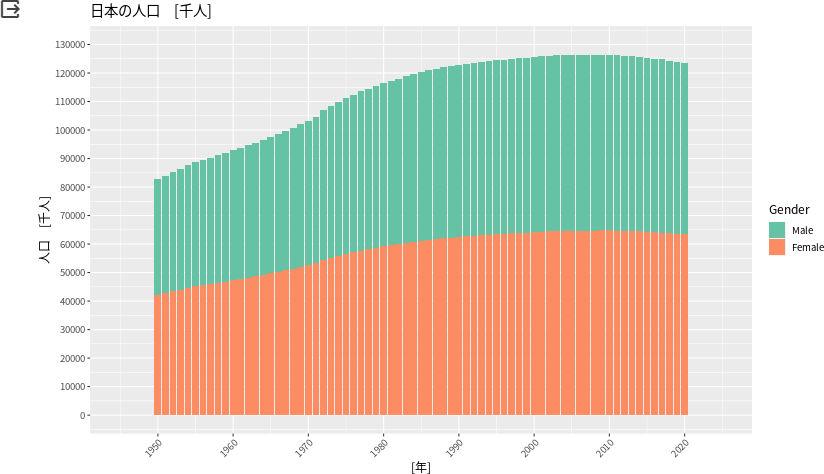
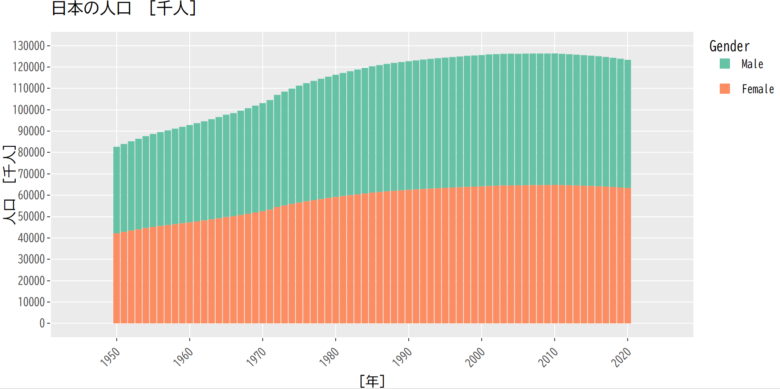
以下のコードでggplotを使ってグラフ作成してみます。(ちゃんと日本語フォント使えるかな。。)
# Rの出力サイズを変更しておきます
%%R -w 800 -h 480 -u px
colors <- brewer.pal(8, "Set2")
family_sans <- "BIZ UDGothic"
family_serif <- "BIZ UDMincho"
p <- df_long %>%
filter(Gender != "Both") %>%
mutate(Gender = factor(Gender, levels=c("Male","Female","Both"))) %>% # mutateでGenderのfactor型の順番を書き換え
ggplot(aes(x = Year, y = Population, fill = Gender)) + # ggplotのコード連結は"+"を使う
geom_bar(stat="identity") +
scale_fill_manual(values = colors) +
scale_x_continuous(breaks=seq(1950, 2020, by=10),limits=c(1945, 2025)) + # Xスケール
scale_y_continuous(breaks=seq(0,130000,by=10000),limits=c(0,130000)) + # Yスケール
theme(text=element_text(family=family_sans, face="plain", size=12), # フォント設定
title=element_text(face="plain"),
axis.title=element_text(face="plain"),
axis.text.x = element_text(angle = 45, hjust = 1) # X軸の数字は45度斜め文字に
) +
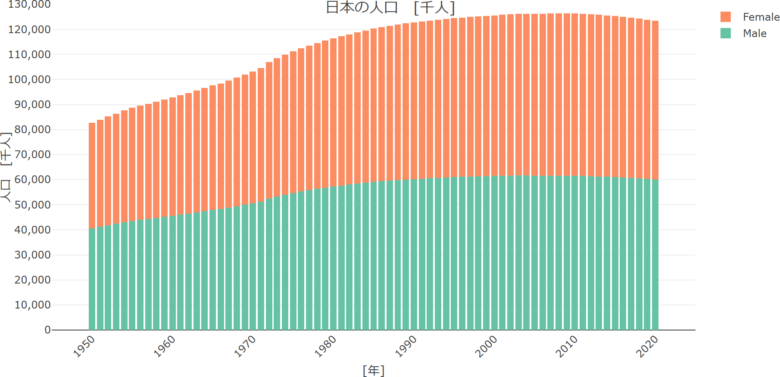
labs(title = "日本の人口 [千人]", x = "[年]", y = "人口 [千人]") # 日本語化
p加工後のggplot出力。
plotly変換して、ブラウザの別タブ出力してみます。
%%R
ggplotly(p) %>% # ggplotで作成したグラフ"p"をplotlyのグラフに変換
saveWidget("p.html") # HTMLファイルで保存PORT = 8000
PATH = '/p.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)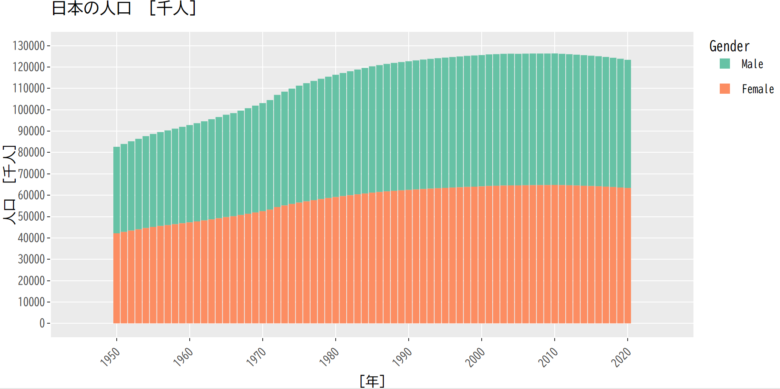
Rのplotlyでグラフ作成
次に同様のグラフを最初からplotlyで書いてみます。
%%R
colors <- brewer.pal(8, "Set2")
family_sans <- "BIZ UDGothic"
family_serif <- "BIZ UDMincho"
p <- df_long %>%
filter(Gender != "Both") %>%
mutate(Gender = factor(Gender, levels=c("Male","Female","Both"))) %>% # mutateでGenderのfactor型の順番を書き換え
plot_ly(x = ~Year, y = ~Population, color = ~Gender, type = 'bar') %>% # ggplotと違う書き方
layout(title = "\n日本の人口 [千人]",
xaxis = list(title = "[年]", tickangle = -45, tickvals = seq(1950, 2020, by=10), range = c(1945, 2025)),
yaxis = list(title = "人口 [千人]", tickformat = ',.0f', tickvals = seq(0,130000,by=10000), range = c(0,130000)),
barmode = 'stack',
colors = colors)
p%%R
ggplotly(p) %>% # plotlyで作成したけど、plotlyのグラフに変換
saveWidget("p.html") # HTMLファイルで保存PORT = 8000
PATH = '/p.html'
#サーバー立ち上げ
!nohup python3 -m http.server $PORT > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(PORT, path=PATH)最初からplotlyでつくると若干印象が変わりますね。

ちなみにplotlyはインタラクティブなグラフなので、拡大縮小、凡例のMale,Femaleの表示/非表示などできます。
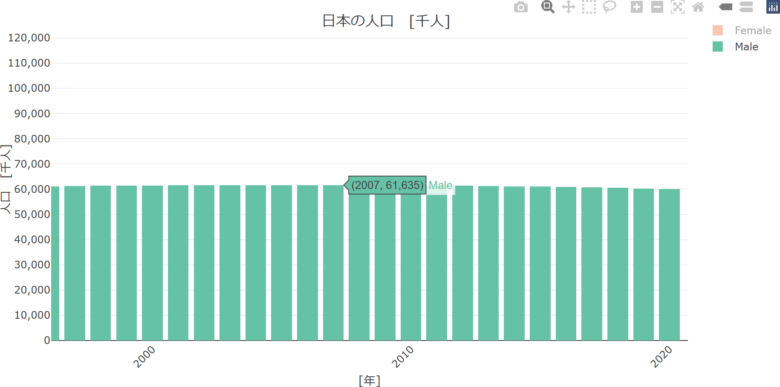
おまけ。インタラクティブなグラフなのでアニメーション加工もできます。修正箇所は2か所だけ。
%%R
colors <- brewer.pal(8, "Set2")
family_sans <- "BIZ UDGothic"
family_serif <- "BIZ UDMincho"
p <- df_long %>%
filter(Gender != "Both") %>%
mutate(Gender = factor(Gender, levels=c("Male","Female","Both"))) %>% # mutateでGenderのfactor型の順番を書き換え
plot_ly(x = ~Year, y = ~Population, color = ~Gender, type = 'bar', frame =~ Year) %>% # ★frameをYearで変化させます
layout(title = "\n日本の人口 [千人]",
xaxis = list(title = "[年]", tickangle = -45, tickvals = seq(1950, 2020, by=10), range = c(1945, 2025)),
yaxis = list(title = "人口 [千人]", tickformat = ',.0f', tickvals = seq(0,130000,by=10000), range = c(0,130000)),
barmode = 'stack',
colors = colors) %>%
animation_opts(100, redraw = F) # ★アニメーション表示
pうーん。簡単にアニメーションにできたけど、見づらい。。
Pythonのplotlyで同様にグラフ作成
最後にPythonのplotlyでも同様のグラフを作成してみます。データはRからdf_longを読み込みます。
Pythonで書くと、ちょっとコードが長くて、Rのパイプ(%>%)の表現と比べて直感的に理解しにくい?かも。
import rpy2.robjects as robjects
from rpy2.robjects import pandas2ri
import plotly.express as px
import plotly.graph_objects as go
import pandas as pd
from plotly.subplots import make_subplots
# Rのオブジェクトを読み込む
df_long_r = robjects.r['df_long']
# RのデータフレームをPythonのpandasデータフレームに変換
# Rのfactor型や日付型はPythonで使う場合は注意
pandas2ri.activate()
df_long = robjects.conversion.rpy2py(df_long_r)
# brewer.pal(8, "Set2")に相当する色を定義
colors = ['#66c2a5','#fc8d62','#8da0cb','#e78ac3','#a6d854','#ffd92f','#e5c494','#b3b3b3']
# データフレームをフィルタリング
df_filtered = df_long[df_long['Gender'] != 'Both']
df_filtered['Gender'] = pd.Categorical(df_filtered['Gender'], categories=['Male','Female','Both'])
# プロットの作成
fig = go.Figure()
for gender in df_filtered['Gender'].unique():
df_gender = df_filtered[df_filtered['Gender'] == gender]
fig.add_trace(go.Bar(x=df_gender['Year'], y=df_gender['Population'], name=gender))
# レイアウトの設定
fig.update_layout(
barmode='stack',
title="\n日本の人口 [千人]",
xaxis=dict(
title="[年]",
tickangle=-45,
tickvals=list(range(1950, 2021, 10)),
range=[1945, 2025]
),
yaxis=dict(
title="人口 [千人]",
tickformat=',.0f',
tickvals=list(range(0, 130001, 10000)),
range=[0, 130000]
),
colorway=colors
)
fig.show()import plotly.io as pio
# グラフをHTMLファイルとして保存
pio.write_html(fig, 'p.html')
# サーバーを立ち上げてHTMLファイルを表示
!nohup python3 -m http.server 8000 > server.log 2>&1 &
from google.colab import output
output.serve_kernel_port_as_window(8000, path='/p.html')同じように出力できました。
本日は以上です。
お疲れさまでした。

